


WTF is AI reasoning?
SOTA #5: Why current AI should be called "Artificial Skills" not "Artificial Intelligence", and what comes next


Visualize with me.
The year is 2009. We’re somewhere in the French countryside. MS of Eng, first year, algebra class.
We’re getting back our tests from the previous week. People are commenting on their grades and such. Most people are unhappy as it is a “tougher” class and get very poor grades.
Yet- that blond guy. The “front row guy,” who always sits right next to the teacher’s desk, once again got a top score. Let’s call him Augustin.
Seeing this, I roll my eyes. I don’t get it. Augustin barely belongs here. His IQ is 40 points lower than everyone else in the room. He always makes everyone late for lunch by asking embarrassingly idiotic questions to the teacher - who always obliges. Augustin constantly asks us questions that make me wonder how he manages to follow the materials.
Yet, Augustin is once again at the top of the algebra class.
The “Augustin of The Front Row” archetype seems to be an omnipresent occurrence in technical fields. Whenever I speak to someone with a technical background, they tell me about their Augustin and express similar bewilderment.
“Augustin” is the best metaphor I have found to explain the paradoxical abilities of LLMs.
What is Augustin’s secret to success? How does Augustin manage to test very well? Well, first off, although he’s not very “smart,” he does have one solid ability: his memory. He compensates for his lower analytical skills by being extraordinarily hardworking and crams through notes and practice tests 15H/day. Before an exam, he practices by doing hundreds of tests until he has seen every variation of every question. Then, when he sits in front of the test, he has memorized so many different answers that he can copy-paste from memory.
He still doesn’t get it, but he REMEMBERS a close enough answer.
Augustin might “test” very well in school, but he usually does not become a strong engineer and usually branches out. At uni, this is evident when he is faced with group projects, as he immediately becomes a burden to any team.
See where I’m going with this? We now have giant models trained on trillions of data points, who do very well on every single academic benchmark*, do amazingly well at some tasks, but unfortunately fail again and again to meet the expectations of “higher-level” tasks, sometimes in a comical way, sometimes costing a lot of money to the people running their projects.
*besides really good ones like ARC-AGI, let’s talk about it in a minute
The background
Who am I to have an opinion on this matter? Nobody, really, just a very obsessed person who spent the last year relentlessly meeting everyone with a strong opinion, and strong credentials. Together with my team, we interviewed over 30 AI researchers working in organizations who have the talent that matters (Meta, Google Deepmind, Microsoft, AWS, Mistral, Huggingface, ServiceNow AI, H, various unis and public labs, etc) and read countless papers about it [you will find a selection at the end]
We culminated this work with a conference on Nov. 8. where we had the pleasure of welcoming three very knowledgeable speakers:

The crux of the matter: Skill vs intelligence
During the conference, Rolf Pfister, the founder of Lab42, who contributed with François Chollet to creating the benchmark ARC-AGI, explained the difference between intelligence and skill.
“Skill involves solving known problems by applying existing knowledge or methods, like playing a game of chess using learned strategies. Conversely, intelligence is about solving unknown problems, which requires creating new solutions or skills.“
As you can imagine, most AI benchmarks focus on testing for skills and testing AI on tasks for which it has been trained. And like Augustin, they test very well on skills.
However, when presented with an intelligence test (which ARC-AGI is), LLMs do very poorly, with o1 reaching only 20% on ARC. This also resulted in the best live takedown exchange I’ve ever seen on X:

What is unique about ARC?
Well, it is exceptionally well designed to test intelligence by presenting tasks the AI has not seen before. It’s very close to an “IQ” test for AI.

The best solutions to the ARC prize today are all LLM-based, and the best one at the time of this writing reaches 55%, while average humans, or even kids, easily reach 85%.
Interestingly, the most recent top solutions are trying to solve ARC using skill, which is not in the spirit of the prize. The current top solutions are doing everything they can to make this a skill problem and not an intelligence problem by either (1) building a corpus of examples for the LLM to train on before trying the challenge or (2) having the LLM generate a library of thousands of possible answers and try them all, brute-forcing the problem.

ARC-AGI is very interesting as it reflects on a smaller scale how LLM maximalists, faced with harder and harder problems, tackle them using LLMs.
ChatGPT does not manage to count “how many Rs there are in the word ‘strawberry’”? Let’s feed it thousands of computer-generated examples for counting letters in a word; next time, it will manage (…and today, it does).
For every problem LLMs fail to solve, LLM maximalists use the “Augustin-tried-and-tested” brute forcing method to build skill.
…and so what?
If the result is the same, does it matter how it is achieved?
Well, even with a gigantic amount of money and resources (which OpenAI and co. do have), the problem space of reality and human existence is very vast. Situations that require intelligence or at least common sense are, in fact, infinite.
This is even truer in enterprise situations where the vocabulary and parameters are specific to the company, and the chance of overlap with enough training examples decreases exponentially.
Continuing my Augustin metaphor:
Scenario 1: if Augustin had to take 1000 subjects, he would not be able to apply his method to everything as he would not have the time to do so. It’s the same for LLM-makers, who, despite their vast funding, have, in the end, limited research teams to design the training pipelines.
Scenario 2: If Augustin were to attend a very poorly documented class (say something as weird and pre-internet as on-device usage of the Fortran language), he would not be able to find enough materials to prepare for the test and would have to rely on his understanding of the course => he would fail.
Consequence 1: many people are rage-quitting on AI in the enterprise for the complex use cases.
As the CEO of a very large system integrator specialized in AI told me over coffee in October: “oh yeah, the party is over - most US CIOs we talk to plan to cut the AI budgets in 2025 as they’re not seeing the expected ROI”.
Sounds crazy, as LLMs are incredible; they generate a ton of productivity when used correctly. However, AI vendors pitched value creation at a level 10x that they can achieve today. Quoting Nathan Lambert (ex HF): “OpenAI has backed itself into a corner with its messaging. Their messaging around AGI soon made people expect this to be in a form factor they know.”
(and no, RAG or fine-tuning is not the solution either, but this is for another day)
Consequence 2: I predict that we are going to see a lot of the “tier one funded” AI-agents-for-X (sales automation, software dev automation…) companies see massive churn in the next few months, as there is a huge gap between the promise the companies are making and the actual ability of the AI to deliver on it.
It’s easy to train on millions of high-school math problems to look smart; there are not billions of super well-labeled examples of successful sales, cold outreach, conversations, or code paired with running and well-designed iPhone apps (unless you are Google and Apple and review these apps).
Customer support, SDRs, and junior devs are not being 50xed / replaced as the giant media articles accompanying the 50M+ rounds claim. They’re still very much needed.
There is even a polite way to phrase this lack of performance now, as people pitch things like: “Our product is “human in the loop.”
Consequence 3: many Augustin-LLM systems are being trained despite being out of touch with the underlying business model requirements:
It’s only worth it for very large markets: if you need to raise 500 M$, implying a >2B$+ valuation, to build your unique training pipeline (by buying and/or creating synthetic data), the underlying market needs to be big enough to support your valuation. For example, we would not see a foundation model to automate OCaml developers (you’re safe, my French friends) or a foundation model for Peruvian law.
Taking less extreme examples, many “midsize” B$ automation problems (as opposed to T$) are out of reach for this approach because the capital requirements are too high.This massively expensive pipeline would likely not be a one-shot operation but a continuous one as the world and data change with it. Salespeople no longer use the ABC method as they did before; frameworks, programming languages, and methods change all the time => what would be the economics of a company that requires all the normal teams to execute its productization and go to market, plus a super expensive training pipeline? The companies who managed to implement this for the “cheaper” hard problems like text and driving had to create usage flywheels from their customers like OpenAI, which ChatGPT and Waymo/Tesla with their fleets of cars that capture training data for them. The problems of Software and sales automation are orders of magnitude more complex tasks, and even if they’re text-based, they would require exponentially more examples to get the model to get it right.
There must be a better way, right?Finally, the skill-trained Augustin-LLM implies very large model sizes and expensive inference costs, especially in a chain of thought context.
(Inference cost = cost of using the model after it’s trained)
I’ll skip the technical parts here, but TLDR, if you need your model to eat a lot of data with subtle nuances, then you need a large model. If you want to make it better at finding the right content relevant to the problem, you will use o1 “Chain-of-Thought” to make it more accurate, basically calling the model on itself 1000+ times. If you want to add agentic logic to the mix (i.e., specialized agents talking to each other and exchanging prompts), it’s even worse. So, in the end, we have a problem solved by 1000s of inference calls on a big model. This is why o1 is limited and unavailable outside the paid plans. It’s f***ing expensive per call. If the willingness to pay off the user is 20€/month, however, and you need your user to perform hundreds of prompts per day, there is likely no economic equation that is a fit for your very large Augustin model.
Consequence 4: if no scientific paradigm change is made shortly, there will be no “GPT 5 moment”. Enterprise pilot project managers and start-up founders,… who have been building on the current AI, hoping that the core intelligence would become better and better and save the performance of their product, now have to realize that it’s not coming. Performance is plateauing.
Don’t get me wrong, I’m not saying that LLMs do not already have a huge impact despite being skill machines. Humans themselves do not solely rely on intelligence but train themselves to be better at their jobs, regardless of their IQ.
Unfortunately for the humans whose jobs are replaced, LLMs have superhuman skill-building abilities, provided there is enough data to feed them. Therefore, many skill-based desk jobs that have abundant documentation are a very good fit for our Augustin-LLM, and the physical skill-based jobs are likely coming next if the economics check out.
LLMs and Image transformers are already replacing some skill-based desk functions, just like computer vision and CNNs had started to do in the previous ten years:
There are less and less accounting assistants adding invoices manually into the ERP (the AI is more accurate in most cases and definitely faster)
There are fewer entry-level graphic designers in gaming companies (Midjourney wrappers are faster to deliver concept images)
The market for freelance content writers has squished
So has the man-made image-labeling market
Self-driving cars are no longer the future but the present, with Waymo and Cruise operating in a few US cities and our portfolio company Wayve working with Uber to automate their drivers.
…
However, contrary to the headlines, the jobs requiring higher displays of intelligence AND/OR harder-to-find training datasets, like sales, software engineering, product design, or level-2 customer support agent, are currently out of reach for our Augustin-LLMs.
… or are they?
Putting the Intelligence in Artificial Intelligence
As we gathered from the previous parts, AI should be named “artificial skills” rather than artificial intelligence. Sure, the result is the same for the more straightforward, well-documented tasks. Still, it creates a performance problem for the higher level, more complex tasks like writing a complex software program end to end with no human support or writing snippets of code in a rare language like OCaml.
Is there a better way?
Is there a way to make this AI more than “a super-efficient matching pattern engine”? Well… there is. It’s just very nascent.
You have two main research directions that are both interesting.
Path n°1/ Next-level Deep learning architectures, next “Transformer” paradigm.
One thing I’m looking forward to finding is more teams working on post-transformers deep learning architectures. Something similar to what Liquid AI is doing in the US. I followed their work at MIT before they turned into a company and was amazed (and could not do anything about it as our mission is to invest in European talent).
The Liquid AI team was inspired by the research on biological neurons found in small organisms, such as the C. Elegans worm, which performs complicated tasks with no more than 302 neurons. Their work resulted in “Liquid neural networks” (LNN), elegant, super-efficient deep learning architectures.
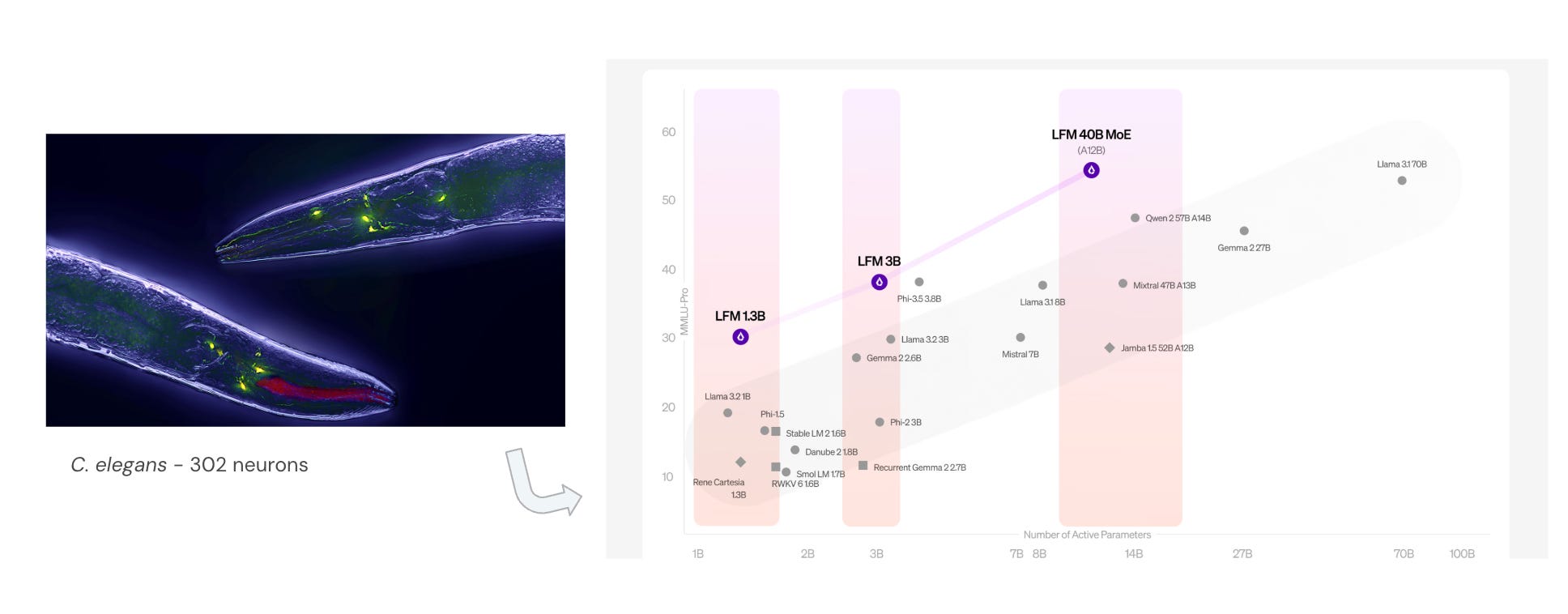
As we saw earlier, efficiency is not exactly intelligence, but it solves a lot of the funding and business challenges associated with our heavy LLMs.
Path n°2/ Neurosymbolic systems
(I will spare you the details as the article is already too long; you’ll get the right keywords from me here and why you should care)
The idea, pioneered by Yann Le Cun and many others, is to pair an LLM or a deep learning system with a symbolic system that validates and brings structure.
It can mean pretty much any architecture that fits this description (some simple, some very advanced; we will focus on the latter). The critical idea is that the “neuro part” of the system can receive reliable validation from the symbolic system (feedback) and, therefore, can converge toward a correct solution, either using reinforcement learning mechanisms or other methods.
The proponents of this approach state that this is a good enough model of how we think when faced with complex situations and, therefore, closer to human intelligence than pure LLM brute force.
We saw earlier that AI has, contrary to us, a super-human ability to build skills. The skill-building will be way more efficient and fast by making it even a little bit closer to intelligence.
The most visible working examples of such systems are at the research stage, with a high concentration of talent within the London Deepmind team and their experience in scaling RL systems (the people who did AlphaGo, AlphaStar, etc). The outcome of their research work is incredible with projects like Funsearch (which turns NP-hard problems into simple heuristics super fast), or AlphaGeometry (which solves Olympiad level maths problems in the lean language).
Who is working on this now? A few examples come to mind:
The OG Deepmind team in London, either within Google or starting their own thing (some of them still in stealth)
At FAIR (Meta’s non-LLM AI R&D team) in Paris, incredible individuals are working on this problem too
In Paris again, Project Numina is attacking the “math reasoning” problem as a non-profit organization applying these methods to help science progress further with super brilliant people behind it as well as a potentially world-changing open-source mindset and the backing to make it happen.
In SF, the CEO of Robinhood partnered with Tudor Achim, the founder of Helm, to build Harmonic AI, which Sequoia immediately funded with a 75M$ inception round.
In London, our portfolio company, Agemo, also tackles the software reasoning challenge with a similar approach.
If you want an even stronger signal, the top, deepest intellectuals of the space, Ilya Sustkever, Mura Murati, and François Chollet, all left their very prestigious positions to “start something new”, showing how little they believe there is to gain from the current paradigm.
That all sounds like more work to do the same AI thing. Why should I care?
You should care if, like me, you believe some of these things:
Scaling LLMs to oblivion leads to what we have now, or maybe something marginally better. There is no “GPT5” unless the paradigm changes.
It now appears that scaled-out LLMs can’t do high-level planning tasks -see the quality problems faced by start-ups who built these agent systems over it.
For the code space, it means you can do code completion for common languages very well, but you can’t do entire software generation (cf the mixed feeling generated by the Devin demo, etc)
To do complex work, you need something more than an Augustin-LLM. Next-level paradigms beyond transformers? Maybe. Neurosymbolic methods? Maybe.
These approaches can be scaled as well, but they are orders of magnitude more data efficient than traditional approaches because their AI is “smart” vs. LLMs who need industrial quantities of information to perform.
Neurosymbolic systems are terribly hard to build (I will not explain why, but “the search space of most problems is too vast” is the short answer). At the dotAI conference in Paris, the founder of Dust, who was previously at OpenAi, explained that he and his team never managed to make it work.
If you’re a $$-minded person, imagine systems that need 1000x cheaper data pipelines and 100x cheaper in inference than agentic/CoT systems, OR, even better, can do 100x more with the same funding, provided you can cast the very rare technical talent who knows how to make these systems work.
Neurosymbolic systems to the test
Let’s go back for a minute to ARC-AGI.

To solve it genuinely:
You should have very few “abstractions” (basic concepts given to the model to understand the problems), such as shapes, colors, etc. Like Ryan Greenblatt, you would not give your model thousands of convoluted mathematical transformations as “tools” that it could use to brute force the problems.
You should also not pre-train the model on thousands or millions of hand-made or generated examples, as we would be building skill, not intelligence (the top scores are all doing a version of this). It would be the AI version of a person training themselves on online IQ tests to do better at a psychometric test for an interview. They will not be smarter, but they will test better.
That’s what the team at Agemo did. They gave their model 10 or so primitives, like the concepts for color and shape. They also never showed their model ARC-AGI examples to let it build skill. It’s all about intelligence, or more plainly, “the ability to converge fast in the trees of solutions of your problem space.” -sic.
Remember how OpenAI o1 tested 20% on ARC-AGI? Well, here is their result.

That’s all for today!
If you would like to know more (after all, it’s only the next main AI paradigm), these are helpful resources:
Yann Le Cun (in 2022!): why we need neurosymbolic systems
More on Neurosymbolic systems: interview of the AlphaProof/AlphaGeometry team by Elad Gil
LLMs can’t reason: the breakthrough Apple article (there are a lot of people commenting it in technical media too)
Stan Polu’s talk at dotAI on the next AI paradigm
LLMs can’t reason, again: Gaël Varoquaux’s take (he is the founder of sci-kit learn and research director at Inria Saclay, was thesis director of Arthur Mensch of Mistral)
LLM reasoning Y or N? super easy to digest commentary on LLM reasoning by Melanie Mitchell, Professor at the Santa Fe Institute, award-winning author in AI
The mainstream media’s take on this (or also here)
Limits to scaling laws by former HF researcher turned scientific writer Nathan Lambert.
The Math case, technical review of the different approaches
AI software engineer: my previous article quite documented on the topic + Devin demo analysis
See you in the next one! If you are not a subscriber already, don’t forget to …
Love,
Marie
PS: ending this on a very French anecdote - all my fellow “MS of Eng” friends from academic, technical universities (“Grande Ecole d’ingénieur” as we call it here) tell me tales of their own Augustin, which prevalence seems to be near 100%.
All, except for those who attended elite project-driven software engineering schools like the EPITA, where all the school credits come from programming projects - there our Augustin archetype fails every class and ultimately changes path.
Curious how this thinking shifts in an o3 world.
The agemo approach seems important still. I wonder how that gets integrated into cot LLM