




Hello friends, I’m Marie Brayer, GP at Fly Ventures, inception stage VC for technical founders solving hard problems. I spend a lot of time on the state of the art of the things that I like and turn them into pages of convoluted exploration. Enjoy!
SOTA #2 - The AI Developer, part 2
Last week, in Part 1, we covered code generation and ended up discussing Copilot Workspace and Devin. TLDR, we discussed the tools that aim to support developers in taming code bases and producing more code.
Today we’ll reach further. Could we have an AI system that builds complete, working software? Now we have the AIs that can compose and correct code “sheet music”, which is fine and good,… what if we now want the entire song with the trumpets and choir?
What if we want a “Midjourney of Software”, not a very smart code editor? Is there a next-level paradigm? What are the technical blockers to achieve it?
To spare your context window, the article is split into 4 sections:
8/ What do you mean by “generating software from a prompt”? We will use four simple examples to display the current limitations of AI in generating software from a prompt.
9/ Low-level blockers to the “Midjourney of Software”: we’ll discuss the three main obstacles in the path toward a model-centric approach.
10/ Midjourney of Software, option 1: the mega verticalized MoE Meta CoT model: Exploration of what an end-to-end “LLM” solution would look like.
11/ Midjourney of Software, option 2: the Hybrid approach: Examination of a possible hybrid approach (between traditional machine learning and LLMs) as another potential solution for AI-generated software.
12/ Closing remark: the contenders: Final thoughts on the current leading players
8/ What do you mean - “generating software from a prompt”?
Let’s go back to why people were excited about Devin. It’s because, for the first time, people seemed to have overcome two of the major blockers for unlocking the true value of LLMs building software beyond the Copilot use cases.
I’m not longer talking about editing / bettering code or increasing devs’ productivity, I’m talking about the promise that gets everyone excited: generative AI for software. The “Midjourney of Software”, is the chance to allow even non-technical people to generate not only code but working software.
People yearn for this. This is the true unlock.

Generating Software is a different business case from self-driving cars though:
“The difference between [AI building software] and self-driving cars, is that a company can take a look at that and say “well this is clearly better, no lives at risk, let’s go do it”’. - Eric Steinberger, CEO of Magic
“I think it [the productivity gains from that unlock] looks like this”

Unfortunately, for now, as good as they might be at completing and correcting code, LLMs are incapable of creating software.
I hear you, in the back: “But I have seen so many amazing Twitter demos with ChatGPT generating entire video games!!”.
All of them are cherry-picked limited examples and lucky ones. They’re the equivalent of having a self-driving car drive in a straight line on a test road: underwhelming.
If you want to make a great Twitter demo, you can ask ChatGPT to generate a full Pong game in Python. It will do it, as the Pong game is part of its training data - it’s a common interview test for developers- and because all the logic fits into one small file.

It’s time to experiment by ourselves. To get you to grasp the many dimensions that get LLM to fail at this task, let me take 4 super super super simple problems and feed them to gpt4.
Let’s see if we can get working programs with no human supervision.
Use case #1: a basic website with an API call. We’re going to build a weather app that asks for the user’s location and then gives them the weather of the upcoming week at this location, all on a web interface

After some prompting, GPT4 gave us 2 files: the app's HTML, and the logic in a Python file (it chose to use the web Python framework Flask). We created these files manually and copy-pasted the code there. GPT4 wanted us to use the OpenWeatherMap API. Therefore, we had to create an account and get an API key. Then we had a working local app that only I can use, on my computer. You can check the code here.

⇒ How did it do? Let’s say “okay” 🤷♀️, 7/10.
We had to do manual work on our end to get it to run, but at least the code was correct and it did what we asked, even though it’s just on my machine and the website is ugly and not showable to a user as is.
In a minute we’ll realize that this “success” was based on luck.
Use case #2: using external models and APIs. Let’s build something a bit more complex: we want a program in Python that takes a WhatsApp voice message file as input, uses whisper or any other similar tool to generate a transcript, and then translates it to French.
I used my code editor to copy-paste the code produced by gpt4 and opened my Terminal to run it locally. I followed the setup instructions as well to install the packages (libraries) required to run the code.
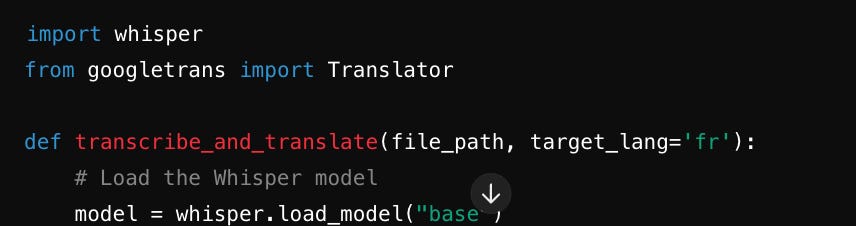
Immediately, we have a major problem. It hallucinated the existence of a pip package (a library) named “whisper”.

After some prompt and back, it finally remembers the correct one

⇒ 0/10 ❌ - The code would have never run if it was not for my intervention, despite the simplicity of the ask
Use case #3: “high IQ logic”. For this one, the complexity is in the logic. I’m asking gpt4 to write a program in any language that takes a CSV file as input (an Excel file) with n rows (say different e-commerce items) and returns a CSV file with the original data plus for each line n-1 similarity scores between each item and every single other item.
Algorithms like these are used by marketplaces to deduplicate items. They are used to identify when a merchant reposts its product with slightly different names and pictures to appear multiple times in search results. Algorithms like these are also used to recommend similar products to a customer.
Of course, I did not expect a production-grade solution or anything advanced, I just hoped for something a data scientist “summer intern” would produce.
Here’s what I got on the first try

This first result is 100% unhelpful because my e-commerce product properties are mostly text, not numbers. But alright, I did not tell gpt4 explicitly that I wanted similarity over text properties. Let’s tell him.
It offers a v2 that can handle text properties. This one runs without a major bug but is total garbage. This is a screenshot of the resulting CSV file:

What do you need to see here? I created an Excel file with 20 e-commerce products, among which two (#1 and #11) have exactly the same data, and the only thing that differs is the merchant ID. Yet somehow the algorithm calculated a better proximity score between products 1 and 2, which are completely different products.
⇒ 1/10 (not zero as the code ran on the first try) ❌
Use case #4: the ultimate test, a basic iPhone app
This time, we would build a simple iPhone app. The app would let the user take a picture of a book, extract the text with OCR, and read the text aloud. I wanted to build this app so that my 6-year-old kid could self-correct her reading and progress faster.

What I thought would be a 2-hour task took well over 8 hours. Even with a considerable amount of help from me, gpt4 could never produce the one page of code correctly (all the logic of the app fits into one file, the “ViewController.swift”).
⇒ 2/10 ❌
- never even produced the right steps to set up my XCode project, as Apple had introduced a new paradigm to build iPhone apps a few months prior and all its information was wrong/outdated / a mixture of the old and new paradigms
- never got the architecture and logic right
- hallucinated methods to use the camera that were no longer valid
- hallucinated text-to-speech libraries
- forgot all the time context and code I had given him previously
- I ended up coding the project myself in one hour once I decided to forgo ChatGPT, switch to a YouTube tutorial, and only use it to fill the functions. You can check it out here
- not 0/10 as it wrote some of the functions correctly once I designed them

9/Low-level blockers to the “Midjourney of Software”
Let’s summarize what we observed from our tiny examples, and augment them with the learnings taken from scientific articles and empirical evidence
Even when the code produced is “correct”, it’s just code: you need to set up the environment, the libraries, the running environment, etc which sometimes is simple, sometimes not. It for sure is not suitable for people who have never coded in their lives and cannot pip install things!
You don’t need to know how to draw or the laws of photographic composition to get Midjourney to produce an image good enough to use on a marketing post: why should you need to know how to use the Terminal to generate software?
I was very excited when Vercel announced their UI building AI V0, for this very reason: Vercel has the “running platform”. However, as their customer base is developers, it’s still very much a dev tool.Output is not robust: a lot of small things in the code are incorrect or hallucinated (library names, path, i/o formats, names of versions, and methods) ⇒ our examples show it is true even in Python where gpt4 is supposed to shine. For the Swift language example (Swift is the iPhone programming language), which had some major changes in the last six months: it was a dreadful blocker. I can’t imagine how bad it must be in newer or more nice programming languages where the training data is sparse.
When you ask for high-IQ reasoning, it just can’t do it (← important)
When you ask for something a bit broader than just a function with an API call, it can’t do it at all (← important too)
Why do we have these problems?
PROBLEM 1: the damned CONTEXT WINDOW
We covered this in Part 1 of the article. See how fast we came across this problem? The context window refers to both input and output. This means that the model has a maximum number of tokens it can consider for understanding (input) and generating (output) text within a single request. The total tokens used by both the prompt and the model's response must not exceed this limit.
One of the consequences is that even if this was possible (our Use case #4 is still fairly small, but likely too big for the optimal window of ChatGPT) it could not, to this day, generate an entire basic iPhone app “in one go”. We could maybe overcome this issue for the smaller programs with the Gemini 1.5 model and its super large context window, but then we would be faced with the biggest problem of all.
PROBLEM 2: LLM DO NOT REASON
I’m entering scientific debate territory here, but hear me out.

LLMs are token prediction engines. By themself, they don’t possess the ability to reason.
ChatGPT in 2022 was a strike of genius not only on the model side but on the experience side, as they managed to offer a user interface that showcases this ability into a magical experience through the chat interface. By constraining the user's input and the framework (it’s a conversation), it focuses the user's attention on what the LLM is good at (finding a relevant answer, compressing/retrieving information).
The nature of these models, their training and the way they interact constitutes the secret sauce of OpenAI and was of course not published BUT now everybody has converged into a few main concepts that helped not LLMs but LLM systems mimic reasoning.
What is awesome in the current time is that there is a literal breakthrough every few months.
In 2022, people from Google Brain figured out that prompting the LLM to explain its reasoning as it goes, and therefore recursively using previous logic yielded a massive unlock, as it was a way to overcome a core problem LLMs have by processing information sequentially. The correct name for this breakthrough is the chain of thoughts (CoT) prompting, and big up for the team at Google Brain who came up with that simple and elegant idea (breakthrough article here).
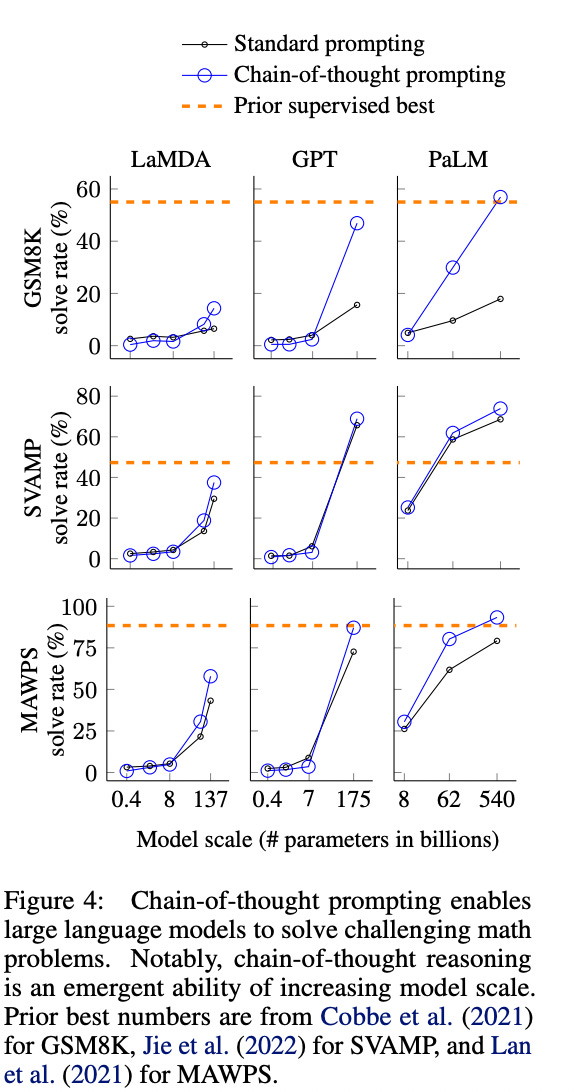
Crazy how such a “small” idea, at Prompt level, changes performance in reasoning tasks significantly. And of course, it has its meta version (ie the methodology for all types of prompts, to add to the LLM meta prompt). I could bet that local versions of this MetaCot idea are present in all last-gen LLMs meta prompts to help them reason better. ChatGPT does this cute thing whenever you prompt it with a McKinsey interview-type question where it starts by laying down its plan, then executes it.
CoT is a big thing, but there was a similar size (bigger ?) breakthrough in 2023. Hint, Mistral made this one famous when it beat Gpt 3.5 with a much smaller model. It’s the Mixture of Experts (MoE). The idea is to have multiple specialist LLMs tightly coupled into a big one. This was the breakthrough that led to the newer generation of “LLMs” such as gpt4 (trillion parameter size) which were supposed to be impossible to infer with the initial “dense” models (= “one block models”)

10/ Midjourney of Software, option 1: the mega verticalized MoE Meta CoT model
Using state-of-the-art research in prompting and training methods to infuse reasoning into LLMs, is there a correct way to train an MoE model with a huge context window capable of writing an entire software piece?
The team from Magic seems to be heading in that giant model & context window direction but if you’ve followed the math all along, you now understand why they raised a 100M$ Seed round. It’s barely enough to do anything - and your margin of error to experiment and be wrong is extremely costly.
“In the end [when you’re training an LLM], you can optimize all you want, if you want next-level results, you need to throw a massive amount of data and RLHF at the problem. Your value, then, as a researcher is to know where to explore - ie where you want to add/generate data- to make the performance better” - Source: a friend of mine from FAIR.
HOWEVER.
Training/feeding to your model every single reasoning task that exists is probably impossible. Did you have that person in math class in high school who learned from memory all the math exercises to ace the test but was completely unable to explain them back to you? no beef to you, blond girl of the front row. This person is the human equivalent of LLMs who have been fed millions of examples of reasoning tasks.
They can solve problems that they have stored in their memory by copy-pasting the logic but are not, actually smart.
If you want to see an example of the blind spots generated by this method, I offer you this Austrian Youtuber’s trick experiment. Humans and older LLMs manage to get it (mostly) right, but the newer LLMs that have MoE training or MetaCoT (gp4, Codestral, Claude 3.5…) fail it every time as it is not part of their reasoning tasks corpus, but the writing of the prompts tricks them into thinking it is:
“Stanford provides financial aid to families with low income. They pay 90% of their official fees. If a poor family with 6 children will send all children to Stanford, at what time will they have enough money, received from Stanford, to send the 7th child to Stanford, if they have no money at all??"
You, as a human, likely reply with one of the three following correct answers
(1) “You told me that they have no money. They can actually send zero of their children to Stanford, as they cannot cover the remaining 10%.“
(2) “The 90% covers the scholarships of the first 6 children, they cannot use that money to pay for the seventh, as they have “no money”. I assume you meant “no money” figuratively, so the little money they have left will be used to pay for their living expenses and for the 10% tuition cost that remains. There is no extra money coming from this to fund the seventh child's tuition cost.”
(3) If you are very observant “You told me that there are six kids in this family, not seven, your enigma is incorrectly worded”.
Well… Claude 3.5 Sonnet, the best LLM today, the one who beats gpt4 on the benchmarks goes into very elaborate calculations that fit the patterns they got at training or in their meta-prompt… and gets it wrong.
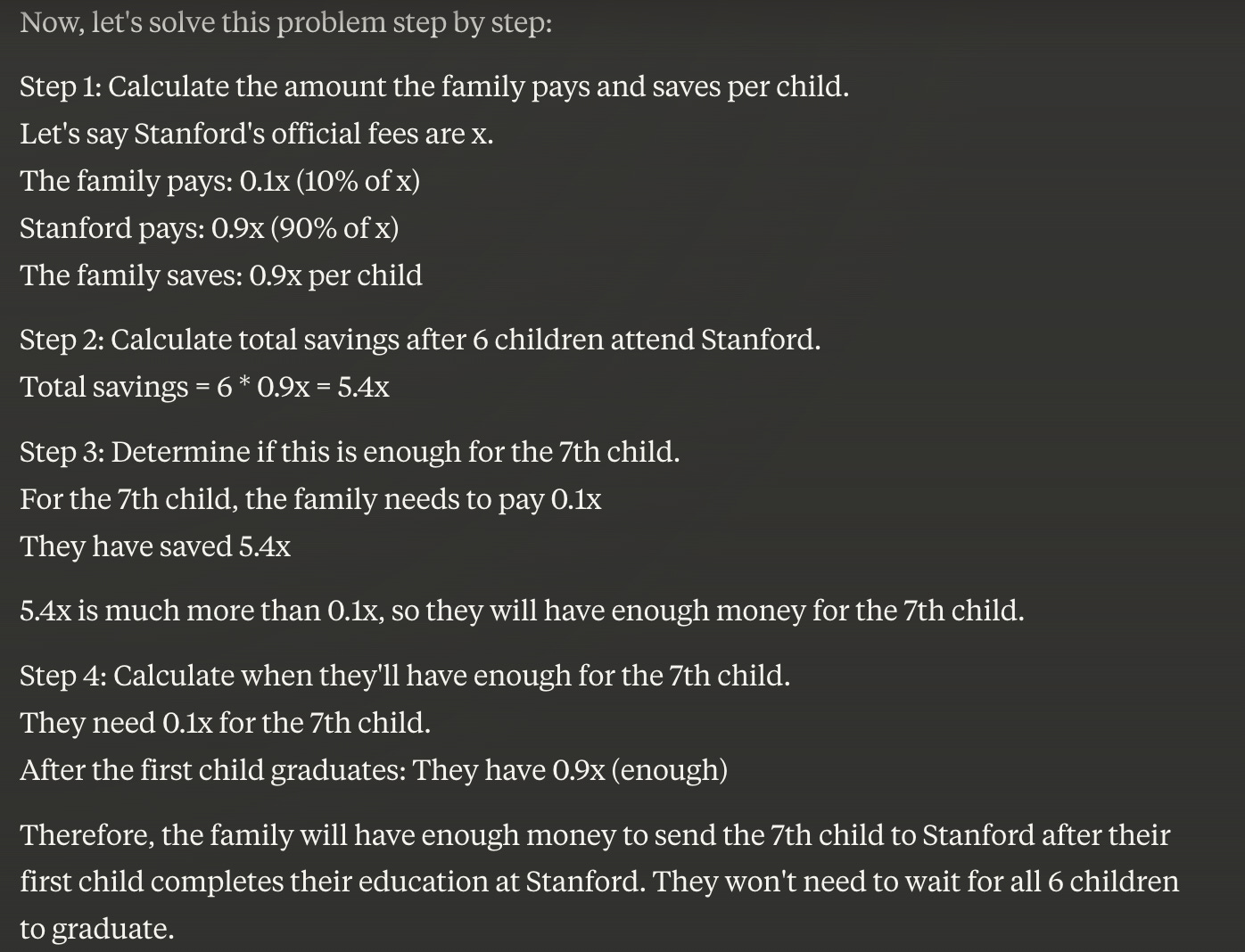
This idea of feeding all possible problems in the world to LLMs is currently the main path taken by the industry, as it works well enough that the user experience for the “Chat” interface is nice enough. When you need reasoning for real though, like we very much do to generate software, the cracks appear!
[We’ll look at the SOTA of LLM Reasoning in a future article, as cool research is brewing, but this is not a solved problem to date]
***
Let’s conclude and summarize the major challenges preventing LLMs from achieving software generation:
the “packaging” problem: removing the need for the user to use the Terminal / running the software automatically etc. Devin showed us one way to do this. I’ve seen others. It’s an engineering and product problem. => likely solvable
the context window problem, with a potential business model problem attached: if every request costs 17$ of inference costs, aka 30 minutes of engineer salary, it sucks. This problem is the one that might go away the fastest though when you look at the SOTA, as many GPU-rich people are interested in solving it. => will at least get better
the reasoning limitations => This is for sure the main problem.
Does this mean that we should benchmark teams working on the “Midjourney for Software” not on the SWE-benchmark that Devin and others use to show their progress but on something like François Chollet’s ARC AGI (the reasoning benchmark)?
It would make sense to me.

11/ Midjourney of Software, option 2: the “old school” ML approach, coupled with LLMs
The other idea is to build, not just one giant model, but a combination of different models (LLMs or old-school ML) working as a group.
It’s less appealing to some, as you cannot then go around and pitch to VCs that you need 200 M$ to train a trillion-parameter model because you are not doing that, you are using a cheaper hybrid approach.
However, at the end of the day, you do not need 1B $ in training costs to get this to work. The talent pool required is different from the end-to-end massive model solution. You do not need to hire one of the happy few who has the skills to train very large models (who all currently work for Meta, OpenAI, Google, Mistral, Anthropic, etc. at very high salaries), you need very good ML Researchers and Engineers who have experience with complex ML systems, once you have found the correct pipeline. Granted, the talent pool is as almost as small as the first one, but overall, this play has the advantage of being infinitely less capital-intensive.
Earlier in part 1, we discussed how GitHub Copilot is made of (1) a classifier model coupled with (2) a fine-tuned GPT4 model and (3) an index of the codebase. This approach makes possible sub-100ms inference time, that users require to want to use a code completion tool.
GitHub Copilot is to date one of the most adopted AI systems worldwide and fits this “hybrid” description, as it incorporates reasoning through the addition of a symbolic* system (the classifier and the indexation).
*I hope I’m using this right
How would our Midjourney of Software look with this hybrid approach?
Well, this is a discussion for another time my friends, as I feel that I already pushed well over your context window!
12/ Closing remark: the contenders
A friend of mine working at FAIR, close to the topic as he’d been asked multiple times to join AI companies as CTO/CSO: “If you want a solid research team in your startup, you have to start with one solid person with a relevant research background in the founding team - then that person can attract other strong profiles. I’m worried that some of the teams out there are not up to the task, unfortunately, and too late in their equity story to attract the right core researcher”.
With this in mind, if we comb through all the teams who pitch “Midjourney for software” but don’t have this anchor researcher, the pool of good candidates is … quite limited.
Who has this anchor researcher as a founder?
end-to-end Model approach: Magic, backed by Nat Friedman looks very solid technically and has the financial backing to try this costly approach at the right level
Neurosymbolic approach: there is also a European contender with a solid technical team - hint, it starts with an A ;-)
“Mega-Copilots”, who will likely join the race, we discussed Cognition, and although their communication methods are a bit much, the team has the right background. Factory, which recently raised an A from Sequoia, also looks very solid. And of course, the GitHub Copilot R&D team is very strong, has access to the most data and customers, and a live product (Copilot Workspace).
Just as self-driving cars have always been “2 years away” for about ten years, I think we’ll need a little bit of patience before we see an extremely capable Midjourney for Software. When we get it though, it will be a game-changer.
Thanks for reading - don’t hesitate to react or comment, either here or by email (mary@fly.vc)!
→ We’ll discuss LLM reasoning more in-depth in a future article. Stay tuned and expect more hand-made examples and funky links to ArXiv!