


LLMs in the Enterprise [H1 2024]
SOTA #3


LLMs in the Enterprise - ugh, so March 2024… Or is it?
I have encountered many long-winded vision pieces but have not found a really technically infused analysis. So here you go, here is one with some contrarian views.
No dream selling, no doomsaying :)
This piece is based on insider testimonials from Enterprise CIOs and key people from Dataiku, Palantir, ServiceNow, and Mistral—among the rare companies selling enterprise-grade LLM products.
So, what are people doing with LLMs in the Enterprise? Today, we’ll look at the build case.
PART 1: the build case
I. What are the Main Enterprise Use Cases
“COMPUTERS DON’T SPEAK FRENCH”: Transforming Human Language into Computer Actions
“TMI FOR HUMANS”: Helping Humans Make Sense of Too Much Information
“MORE SPAM PLEASE”: Helping Humans Produce Content Faster
II. Enterprises Want LLM Tech Built Internally
III. Mistral and other DIY LLMs
IV. Examples, dammit!
Conclusions: the factors limiting the adoption of LLMs in the Enterprise might not be what you think
I. The three prominent Enterprise use cases
If you listen to people in the trenches with enterprise customers, the main ROI-yielding use cases for LLM in the enterprise can be bucketed into three main categories.

The first bucket, “COMPUTERS DONT SPEAK FRENCH,” involves enhancing customer support functions and similar areas through automation, turning LLMs into a super robust automated ETL, and turning unstructured data into code, a database, or an API call.
A second bucket, that we are going to call “TMI FOR HUMANS“: search, discover, and collaborate more effectively, making sense of lots of unstructured data.”
A third bucket, called “MORE SPAM PLEASE,” is content creation for various functions such as marketing, product development, legal, etc.
Let’s dig into it.
1/ COMPUTERS DON’T SPEAK FRENCH
LLMs as user interface: transforming human language into computer actions: by far the coolest, yet less obvious and advertised use case for LLMs
All applications in this bucket use LLMs as robust interfaces, designed to transform human requests into machine-readable content or API calls in a system, safely. A perfect application of this idea is the automation of customer support requests and helpdesk interactions.

The aha moment when the entire world realized this fact can be precisely pinpointed to this PR made by Klarna in February. This PR notably led to several call center companies, such as Teleperformance, instantaneously losing 30% of their market cap.

Of course, Klarna’s claims are a bit pushed, and most of the achievement is due to the automatization of the back office, which has little to do with LLMs, but the end result is only made possible by LLMs.

We realized this was a turning point as people in the world of private equity who usually doesn’t care much about emergent tech started pinging us at Fly and enquiring about AI. The importance of this PR was confirmed at a presentation we did at the AGM of one of our LPs (the people present at the AGM represented 100B$+ of assets): out of the 60 managers in the room, about 55 raised their hands when I asked who knew about Klarna’s LLM announcement.
So everybody wants this for themselves, and it makes sense: LLM as “robust ETLs” is the key to unlocking LLM's potential in enterprises and could improve global productivity by 50%:
Eliminate 90% of all customer support, including voice interactions => achievable
Reduce "admin tasks" by 50% => achievable (think “forward to Salesforce/Zendesk/Qonto” but 10x better)
Remove the need to learn complex interfaces by simply "asking" it to do something => achievable
Handle most data input with fewer errors than humans (eg a 2x better Gong.io) => achievable
Prompt instead of code to get a basic configuration of complex scripts and tasks => achievable
2/ “TMI FOR HUMANS”
Helping humans make sense of too much information: the overhyped, misunderstood use case for which LLMs are likely not the right AI
A lot of people want to use the superhuman powers of the LLMs to make sense of massive unstructured data or empower business processes that require multiple siloed teams to come together and produce a result.
It makes sense, as finding similar text, summarizing and synthetising is the core ability of the LLMs, and this is well reflected in the current offers on the market taking advantage of it and augmenting for sure their users’ productivity:
the “neo search engines” such as Glean (B2B), Perplexity AI (B2C), and soon SearchGPT (B2C)
the “text-snippets gatherers” to build custom assistants like Sana Labs and Dust
What makes this bucket overhyped then? Usually, when you talk about LLM helping people make sense of a log of data, people don’t think “better, robust search”. People want to plug chatGPT to a Drive folder and ask things like “Please rank our top 100 customers in 2017 by business volume”.
I’m sad to say that current LLMs seem unable to do this, and there is a good chance, given the scientific literature, that you cannot at all do it with ONLY an LLM. (I’ll explain why in a minute).
Many vendors & startups still pitch versions of this, though, showing a proof of concept that works 20% of the time but will never reach 95%. Most of these products and technologies are based on the idea that RAG (retrieval/augmentation of the LLM with the enterprise data) gets magical results.
So why is that? Why can’t we rank 2017 customers by business volume with RAG?
(1) LLM cannot reason, and you have a good chance of hitting their blind spots with your request. If you want to test this for yourself, you can look at my examples here or here. In one example, I asked GPT4 to rank family members by age (it failed). In another example, I asked it to rank made-up e-commerce products by size (it messes up) or what items require a charger (it forgot six out of the seven items).
My 6-year-old kid can do that.

WTF? Why can’t LLMs sort basic items or say what requires a charger when you see them do seemingly much more complicated stuff?
I leave a longer deep dive into LLM reasoning for next time; subscribe to read it ;-)
For now, trust me on this (or trust Yann Le Cun, if you’d rather): when using LLMs for a simple reasoning task, you have a random chance of success, if it hit one of the reasoning patterns the LLM was trained on, and a healthy chance your analysis requests won’t be close enough to an example it did at training. An analysis which is incorrect a random % of chance all the time is a bit shitty, and of course the chance it produces total garbage compounds with the complexity of the reasoning task.
(2) RAG is a dark art but not dark magic: But… but… what about RAG? Is it not supposed to go and fetch the correct information from the right place?
If you type into a “chat + RAG” system, “Who was our top customer in the last year?” unless a close-enough sentence is explicitly written somewhere in a document and the vector similarity search finds it (i.e. something like “Our top customer this year is Sanofi” from a board pack for example), it will not return anything of value.
The AI will not infer from your request that it needs to find all customers' purchase orders and rank them by contract size. It will just look for a sentence that is close enough.
As most people do it today, RAG is just a robust search; it has zero business logic or analysis. If you want to embed logic into RAG, you’ll have to look into other AI types like GNNs [also no, not graph RAG]
(3) LLMs are not pre-trained on tabular data and can’t make sense of it. At their most unitary level (the pre-training), LLMs are next token predictors for sequences of text. Text, as in not numbers, not tables, not time series. Nothing else but text.
That’s unfortunate, as most data in the enterprise is in an Excel or a BI tool.
OpenAI has been offering some of this capability in their models (notably when you look at the vision demos). They can somewhat make sense of tabular data in the form of a picture. However, the use cases are mostly “advanced OCR” because you quickly hit the same issues.
Better than using computer vision to read a table from its picture, GPT4, and the most novel models are probably better off using function calling to directly call for data in normal databases by using their internal Python interpreter and their ability to write (for instance) SQL requests, but this is barely talked about.
OpenAI’s acquisition of Rockset in June for their “Hybrid search architecture” indicates that this might change.
But…, despite all of these major problems, RAG start-ups raised a ton of money!
RAG-in-a-box companies such as Pryon raised a 100M$ series B in 2023. Pryon was created by the AI pioneers who developed Alexa, Siri, and Watson. Similarly, Contextual.ai does not seem to be live yet, but it has secured a large series A funding.
Vectara, PineCone, and Weaviate … (the vector database companies, the infrastructure players who enable the most common forms of RAG) raised massive amounts of money - damn, there is even a Forrester Quadrant for this now!
I leave you judge to what this means, particularly when new advances in context window size and prompting techniques challenge the usefulness of the classic “vector database” RAG:
A paper from CMU and Tel Aviv Uni, for instance, shows that at scale, for complex tasks like business tasks, in-context learning (a prompting technique where you put a ton of data into your prompt as context) outshines RAG and even fine-tuning in terms of performance and has the added advantage of requiring far less data and skills.

We’ll come back to RAG in a future article. For now, let’s leave it at :
it works fine if all you want is a form of robust search
most people expect too much of it
In some cases, with bigger context windows enabled in the models, you can probably just feed a ton of data into the prompt and not bother with it at all
3/ Third bucket, “MORE SPAM PLEASE”
Helping humans produce content faster: the obvious, well-documented case of productivity increase driven by LLMs
You have already fallen into this bucket if you have used ChatGPT to do your reporting or your substack post. Not me, of course, as, unfortunately, my French-infused, very poor English does not look genuine when I use ChatGPT.
Start-ups have also embraced this category with function-based or verticalized writing assistants, such as Typeface (raised 150M$), Harvey, Jasper, etc. Here, the usage of RAG makes sense as marketers need to keep style and reuse snippets of agreed-upon messages between documents, and lawyers need a better search to find similar cases or cite case law.
LLMs supercharge human productivity not only in generating more text, but also code, pictures, music, and soon, 3D assets or electric signals...
This is LLMs' most straightforward successful use case, notably demonstrated by OpenAI or GitHub Copilot’s revenue.
II. Enterprises seem to want LLM tech built internally as it involves their business data
Now that we know the use cases—interfacing with machines, robust search, and producing more content—how do Enterprise companies say they want to achieve these productivity gains? By buying ready-made solutions or building them internally?
Let’s look at the A16Z survey results, as they have “spoken with dozens of Fortune 500 and top enterprise leaders, and surveyed 70 more, to understand how they’re using, buying, and budgeting for generative AI” - and also they align perfectly with our findings:
Getting productivity from LLMs is taken seriously, and increasingly big budgets are created to fund LLM usage: on average 7M$ in 2023 and 18M$ in 2024 per company

Half of the respondents want to build in-house solutions using open source because they want to control where their data is going.

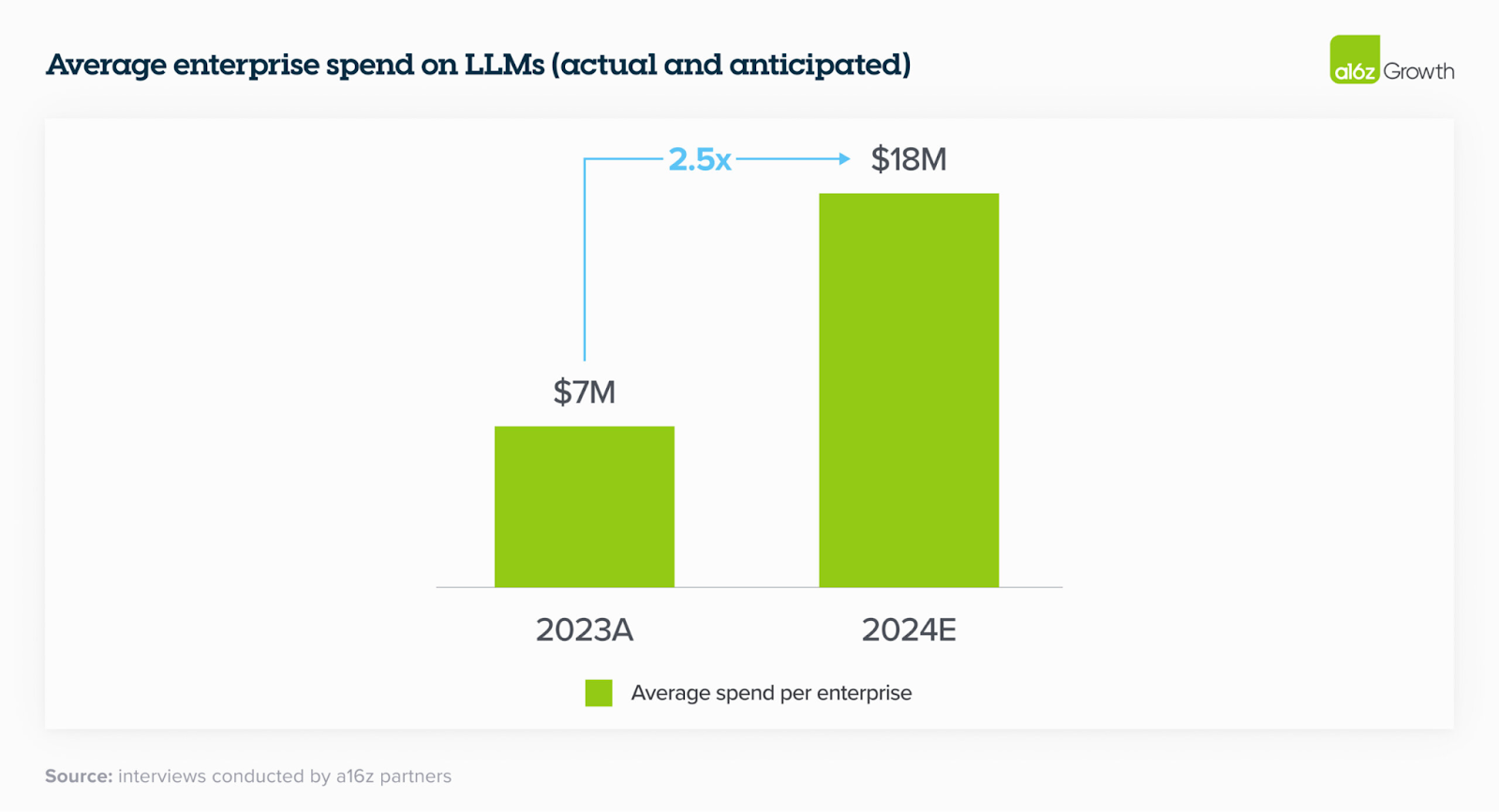
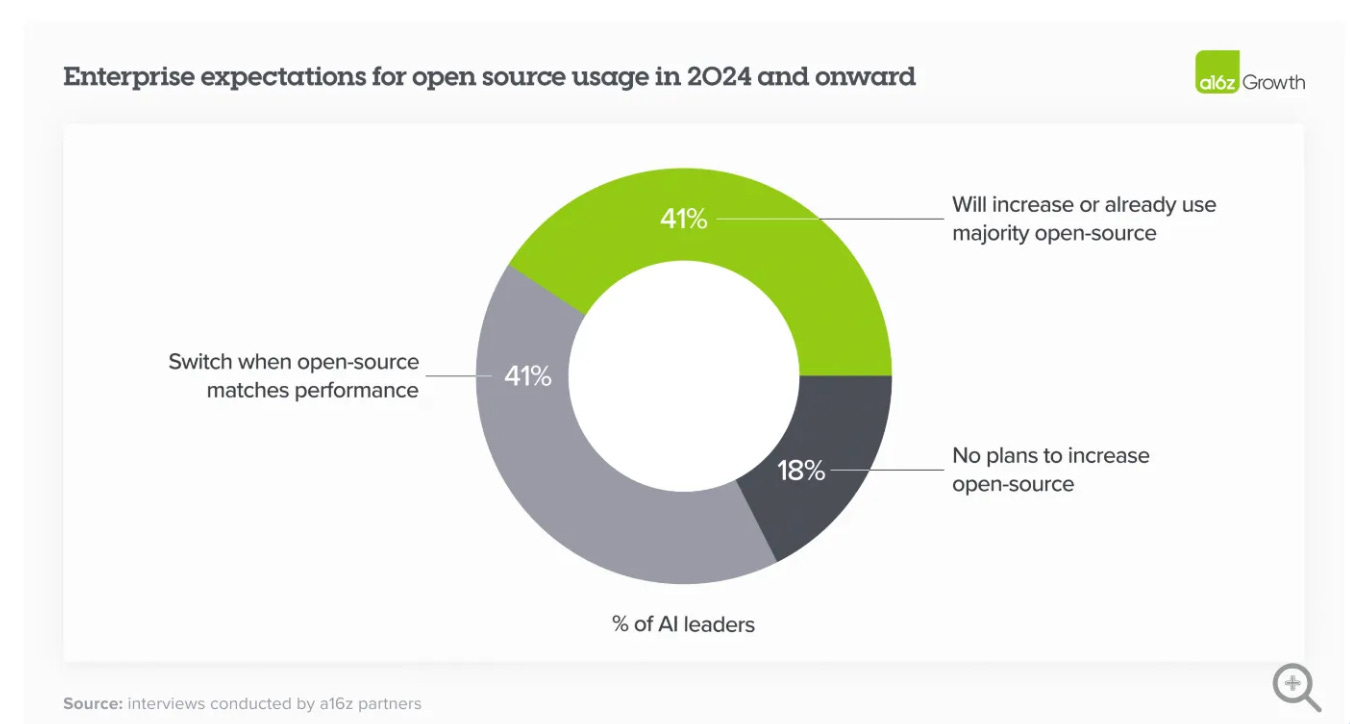

Cost is cited as reason #3 here, but I bet it will become reason #1 in next year's survey when people realize how much scaled LLM pipelines cost.
Gpt4 is a bit expensive if you want to do anything at scale. Take a boring example: say you have a translation pipeline to translate e-commerce product data from English to four languages. Your company, a marketplace, adds one million new products per month. You currently struggle with a translation software vendor and five translation agencies, and porting this to an LLM pipeline looks like a no-brainer.
How much do you think an LLM pipeline would cost?
*Drumroll*… it would cost 192 K$ per month with OpenAI, or 111 K$ of computing costs on Google Cloud if I were to use Mistral or Llama3. For reference, AWS Translate would cost us ~10K$.

The Chief Data Officer of a large e-commerce scale-up (>1B$ GMV) recently told me: “There is a big challenge now with our LLM pilots; you either have something that works but is super costly with the large models or something that just does not work at all with the smaller models. We’re struggling to find the right balance at scale.”
…To researchers everywhere working on pruning / compressing models: thank you in advance for your future smaller LLMs; a lot is at stake!
If you do quick maths on the survey data, it also tells you that c. 75% of the money is spent on pilots, and 75%+ of all the money is currently going to OpenAI**.
Wait, 70% of Enterprises say they want open-source solutions, but 75% of all the money is going to OpenAI? Actually, it makes sense: there is a clear pattern of (1) starting a pilot with OpenAI, which is the majority of the market today, and (2) then wanting to deploy it using open-source or internal platforms that prevent data from leaving to third parties.
It makes sense, as there is ‘no free lunch’ in data science. Enterprise customers are very aware that although compressing the entire internet text data into a model is valuable, much of the value lies in their business data. As we saw earlier, “vanilla” LLMs trained on internet data can’t power our 3 use cases as is, and will need to be mixed with other machine learning / AI techniques.
III. DIY LLMs
Open Source models are a good solution to Enterprise’s need for data and cost control, with Mistral as the spearhead. It makes sense as well for System Integrators (SIs) and “tier 2” Cloud Providers (CPs) who want to provide services around LLMs, are equipped with the right ML people but don’t want to spend $100M to train one.
Like many open source companies before it, Mistral will probably go for a Mixture of Business Models (pun intended) to monetize enterprise customers: OEM/licensing deals with cloud providers, the development of a Platform as a Service (PaaS), and/or an Open Core strategy with paid MLOps tools.
Mistral faces competition obviously from Meta and the LLama models (but the open source terms of Meta, or just the idea of using products made by Meta, might deter some enterprise users). In addition, Databricks’ “ready to fine-tune” Dolly and other models developed by open-source consortiums, such as Starcoder - a collaboration between ServiceNow and Huggingface will play a role.
However, seeing how many non-” pure-player” companies will keep investing 9 figures+ into training models in the long term will be interesting, as the game is a bit more expensive than traditional open-source.
Historical data & ML platforms that already have access to enterprise data seem ideally positioned to train or help fine-tune models that could sweep the market. However, no killer use case or feature has added a clear line to their P&L yet.
Databricks recently released DBRX, a 132B parameter Mixture-of-Experts (MoE) model that they trained from scratch for $10M, with relative indifference from the market. The model, supposed to be state of the art, gained very little coverage (90 HF upvotes, 2.4K stars on Github) and seemed to be more of an advertisement for their new ML suite geared for LLMs: Mosaic AI (they acquired MosaicML, an OSS competitor to OpenAI, in 2023 for $1.3B).
Dataiku has also taken a step in that direction by assisting customers in setting up their first RAG or adding support for HuggingFace models to the platform.
“Large data” platforms, such as Weka or Vast, are gaining momentum with more usage from the GPU-rich crowd as they are better geared towards large workflows that match the requirements of LLM’s use cases. They are designed to handle the problems that only exist at that scale (when you 10x the model size every 1.5y, plenty of infra. parts break down eventually). For instance, handling enormous volumes of random reads in distributed filesystems to train models starts to be a problem with the latest model sizes. However, much like Nvidia (50%+ of the cool data center business is from Meta/Google, etc.), their newfound traction is still mostly from people who develop the models, not the end customers.
IV. Examples, dammit!
We saw earlier that Enterprise customers say they want to build their own LLM pipelines and that there are plenty of platforms for this.
Then, naturally, we must ask ourselves: What has actually been built by these Enterprise customers? How impactful are home-grown Enterprise LLM solutions?
As we are focusing on “build” and not “buy,” we will remove from view:
The consumerized usage of the “vanilla” models (ChatGPT, MidJourney, …) - that amounts to approximately a 2B$ spend in 2023 (1.3B$ for OpenAI)
The usage of LLMs within big closed enterprise platforms, such as the LLM-based features available in the premium plan of ServiceNow / over 2B$ of ARR (we’ll cover this in Part 2)
The usage of LLMs packaged into a SaaS solution (Jasper or other OpenAI wrappers or the existing SaaS players “AI-flying” their products like NotionAI or GitHub Copilot).
Code generation/ developer augmentation, because we already covered this entire topic here
For source material, we looked for press releases and case studies of use cases built internally by large companies with a documented ROI, if possible. Unfortunately, after a full 10-hour session of Internet search (in June), we only found…17.
A. Fargo the Customer Support chatbot #computersdontspeakfrench
B2C Enterprises are also looking for a better way to care for their customers at lower costs. Among the companies doing it internally, Wells Fargo deployed “Fargo,” a virtual assistant that helps customers get answers to their everyday banking questions on their smartphones using voice or text. According to WF, it is seeing a “sticky” 2.7 interactions per session and has handled 20 million interactions (as of Jan. 2024). The feature uses Google’s PaLM 2 and can execute basic actions such as transactions. It is the Wells Fargo version of Siri.
B. Walmart’s internal workforce support chatbot #tmiforhumans & recipe-to-basket chatbot #computersdontspeakfrench
Walmart, the largest retail company in the world, is moving forward with both customer and internal-facing uses of LLMs. They announced their in-house LLM platform in early 2024. They released “My Assistant”, a genAI tool trained on company data that helps workers write job descriptions, summarize data, write emails, guide interviews, and generate ideas. They also announced an addition to their iOS app: an LLM feature that creates shopping lists for customers from a natural language prompt: “Help me plan a March Madness watch party”.
C. Data classification at Grab #tmiforhumans
Grab, the Nasdaq-traded Asian app for taxi, food delivery, and insurance (it’s easier to list what they don’t do), used GPT 3.5 to classify users’ data, saving their team 360 man-days per year. They created a classification pipeline on top of their database that concurrently used GPT and a third-party classifier. They discuss limits to their approach. The first is the GPT token window, which was 4K tokens (3000 words) at the time, and the overall Azure token limit was set at 240K tokens per minute.
D. Easyjet’s internal help bot #tmiforhumans
One of the major use cases being widely experimented with across many companies is to enhance knowledge indexing and access, primarily with RAG. EasyJets created a “speech-to-SQL query answer” PoC in 2023. They equipped their latest control center with “Jetstream”, a database interface giving instant access to 3000 pages of manuals, policies, procedures, and information. They plan for AI-led technology to be placed in the hands of crews as well in the upcoming months. It’s hard to estimate direct ROI on such tasks, and the tools still suffer from hallucinations or non-exhaustivity of the answer.
E. New gameplay from Niantic #morespamplease
On the gaming side, we’ve seen Niantic, the Pokemon GO editor, release Peridot in 2023. The mobile game is a Tamagotchi-like that uses LLMs to generate behaviors for AR pets, making them appear to interact with elements in the real world. Peridot was a commercial failure likely due to predatory pricing of in-app features, but it could pave the way for other ambitious gaming experiences.
F. Automatically generated dialogs from Ubisoft #morespamplease
Ubisoft developed Ghostwriter, an internal tool for writing NPC(non-player characters) text for games. We covered the impact of GenAi on the gaming industry in more depth here.
G. Rufus, the Salesbot from Amazon #tmiforhumans
Rufus, Amazon's AI-powered shopping assistant, helps users make informed buying decisions by answering product-related questions, offering comparisons, and providing personalized recommendations based on their needs. Amazon advertises its ability to streamline shopping, offering insights like what to consider when purchasing specific items or comparing similar products. However, since February’s release, customer feedback has been mixed.
If you’re underwhelmed, no worries; we’re right there with you.
European sidebar: we did not just focus on the US in our research, even though people are clearly more happy to try new things there: in the land of Mistral, H., and Kyutai (🇫🇷), no one seems to be in a rush to announce LLM products either.
Companies like TotalEnergies, Airbus, or CMA-CGM announced a proof of concept, principally for two use cases: improving employees’ queries on their internal databases with RAG or boosting Q&A chatbots for their customers. There are little to no public traces of the productivity results, so we are still far from Klarna’s 700-employee-equivalent performance.
A conclusion on the “build” case for LLMs
So, why are there so few positive ROI cases reported and so few press releases despite the potential for an instant increase in stock price? Whereas overall sentiment towards LLMs is excitement about the potential, the reality is that, except for a few determined use cases in high-tech companies (startups & software vendors), the market has not successfully yet produced clear wins that directly translate to an increase in P&L.
Plausible explanations:
#1: People need to chill a bit, everything is still underbaked: a lot of what’s coming is still not ready to be shown and ‘in the making’. We have to wait, and we will see an explosion of PRs later.
#2💡The limits of LLM technology are overall very misunderstood even by seasoned data scientists because this field is brand new; plus, most of the LLM science is not mature. For example, getting RAG to deliver something other than a disappointing result is “a dark art.” A lot of people who get “33% accuracy” on their pilot don’t measure how difficult (or impossible) it is to reach 99% accuracy with the current models.
#3 👩💻 Insane talent shortage. ML Engineers (not to mention researchers or scientists) who know how LLMs operate are very few. Not everyone is Deepmind and Meta, most companies don’t have a swarm of ML engineers to dispatch to LLM pilots.
Core LLM talent is aggressively pre-empted by the GPU-rich crowd or super-funded startups, or they start their own companies.
We recently had a Senior Researcher in London who was in a portfolio company's hiring pipeline get a direct message from Mark Zuckerberg, offering a 1-1 Zoom call with him, no hiring process, and a huge salary (spoiler: it worked). Google has relaunched its Orwellian secret hiring challenge in Chrome and doesn’t shy away from paying senior engineers well over $1M per year.
Startups still have some charm, but how should the “normal” companies compete?
#4 💸 No business model. The business model of an LLM pipeline is not a given, as the system can cost 1 to 10 euros per inference request (read that again) or more in compute or API costs for complex use cases. It’s not as cheap as running “normal data science” pipelines where the only cost is the team. Everything from finetuning to inference is expensive.
⇒ Massive ROI needs to be present to justify the cost.#5 🚨 Security is a concern. Many people are terrified of it, for good reason. Look up prompt injection and AI Cyberworms.
#6 🤷♀️ It’s not very “ESG-friendly” to fire 90% of your CS agents and replace them with AI. Not everybody agrees with the concept of creative destruction. Just look at what Embark Studios had to go through when using AI Voices to power an experience in a video game instead of using voice actors and how quickly we got protests in Hollywood after GPT3 came out.
An example of this is Visma, a private, profitable accounting software vendor that does not need investor attention to survive. They could very well have made the Klarna PR move as they reached similar levels of LLM-powered back office automation. However, they likely did not advertise their AI automation progress because they were afraid of the possible public backlash.
So, at the moment, it seems that there is an abundance of picks and shovels (150B$) but very little gold, as all these challenges need to be overcome.
We might see it pick up speed as everybody becomes more familiar with this new technology and manages to develop initial use cases.

Thanks for reading, esp. thanks to the ones still on holiday and should be enjoying cocktails on the beach instead ;-)
I'll see you in a week for part II. We will explore who makes money with GenAI in the enterprise (spoiler: Enterprise software vendors).
Marie
Edit: someone sent me, after the publication of the article, this useful collection of deployed use cases made by the creators of DSPs. They, too, only identified <20 PRs.
A big thanks for putting together all your insights and key discoveries—so insightful! 🙏